タイ語(諸外国語)の公文書をOCRでテキスト化して翻訳する

先の記事で、「タイ語の公文書をOCRでテキスト化して翻訳する」という作業を説明したのですが、意外に好評でさらにその後お二人の研究者の知人からその方法について尋ねられました。また昨日タイの大学で活躍する知人にスキャナが手元にない場合のOCRの方法についてお話しをする機会がありました。
仏暦2568年 民族集団の生活様式の保護及び促進に関する法律少数民族の生活の保護および促進に関する法律案(試訳)
タイ現代政治の研究者として著名であるばかりでなく、日本国内の主要メディアにタイの有益な情報を多く提供している水上祐二先生からの情報提供で、「少数民族の生活の保…

なかなかみなさん苦労している様子なので、2025年9月の段階で、僕がベストだと思う方法を簡単にまとめておきます。
もちろんタイ語だけでなく、他の言語でも同じ方法で簡単にOCRでテキスト化できますので、ぜひお試し下さい。
「Google Suite」に登録済(よくわからなければ、「Gmailが使える状態」)であることが前提です。
1 必要となるPDFを準備する
今世界中の多くの政府が資料をPDFで配布しています。このPDFには、「テキストが埋め込まれているもの」「テキストが埋め込まれていないもの」の2種類があります。
例えば2025年8月6日に行われたタイの
ระเบียบวาระการประชุมสภาผู้แทนราษฎร ชุดที่ ๒๖ ปีที่ ๓ 「第9回国会(第一回通常会期)下院議会会議議題」
のリンクから、
เรื่องที่ที่ประชุมเห็นชอบให้เลื่อนขึ้นมาพิจารณาก่อน 「議会が先に審議することを承認した案件」のPDF(文字情報なし)をダウンロードしてみましょう。このPDFにはテキストデータが含まれておりません。
ดาวน์โหลดเอกสาร(文書ダウンロード)の部分をクリックします(下の画像の赤丸の部分)

(中上級者向)なお、「もう十分にGoogle Suiteを使い尽くしているよっ」て方は、この時保存先に自分のGoogle Driveを指定してあげてください。
機種や状況によって違いはあるかと思いますが、これで原文のファイルが手に入りました。なお、以下の方法はJPEGなどの画像フォーマットでも可能です。
(初級向)もし、「単にタイ語のファイルを日本語に翻訳できれば良い」というのであれば、この段階でGeminiにこのPDFファイルを投げて、翻訳を依頼しても大丈夫です。2025年現在で、Geminiはテキストが埋め込まれていないタイプのPDFを読み込み、翻訳することが可能です。Chat GPT5では、テキストが着いていないタイプのファイルは処理できないようです。研究の必要上、原文のタイ語も手に入れたいという方は次のステップにどうぞ。
2 Google ドライブにPDFをアップロードする
Webでのドライブをお使いの方は、Google Suite から、次にGoogle ドライブにアクセスし、ログインします。

画面左上の「新規」ボタンをクリックし、「ファイルのアップロード」を選択します。
このGoogleドライブの中にテキスト化したいタイ語のPDFファイルを選び、アップロードします。
(中上級向)Google DriveアプリをPCにインストール済の方は、ご自身のローカルのGoogleドライブにダウンロードしたファイルを移動してください。すでに1の作業でGoogleドライブにファイルを保存された方は、次のステップに。
3 Google ドキュメントで開く
アップロードが完了したら、Google ドライブ上でPDFファイルを右クリック(または右上のファイルメニューをクリック)します。
表示されたメニューから「アプリで開く」を選択し、「Google ドキュメント」を選びます。
しばらく待つと、Google ドキュメントが新しいタブで開き、PDF内の文字が画像の下にテキストとして表示されます。

これで、PDF内のタイ語が編集可能なテキストデータとして抽出されます。コピー&ペーストで、自由に利用することが可能です。
あなたの目的が、単に「PDFからタイ語を取り出すだけ」であれば、簡易バージョンとしてはここで終了です。
4 生成系AIによる整形・翻訳
タイ国会のPDFをいくつかスキャンしてみて、OCRスキャンの際に様々な変換ミスが生じたり、ページ番号やフッターなどのゴミが入っている可能性が高いことがわかりました。他の国の公文書もそういうことが多いと思います。
そこで生成系AI(Chat GPTやGeminiなど)を用いて、そのような変換ミスを取り除き、またゴミをとりのぞく作業をいれてあげるとよりテキストの精度があがり、使いやすくなります。
次のような形で、生成系AIのプロンプトを書き、ファイルをアップロード(またはテキストのコピー&ペースト)して校正してあげるといいでしょう。
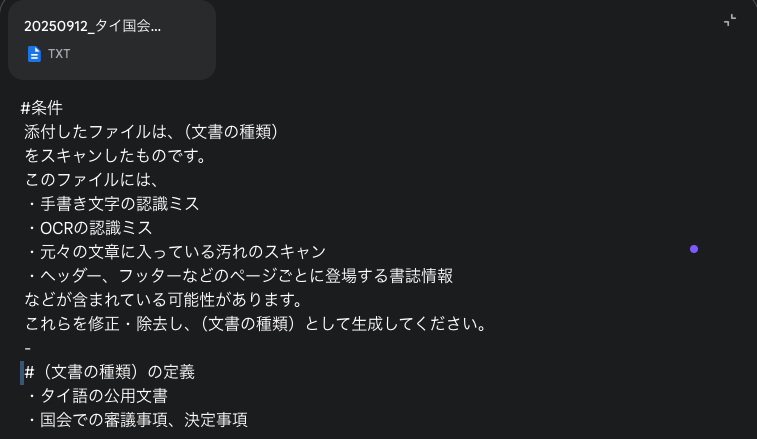
---プロンプト例---
#修正条件
添付したファイルは、(文書の種類)をスキャンしたものです。
このファイルには、
・手書き文字の認識ミス
・OCRの認識ミス
・元々の文章に入っている汚れのスキャン
・ヘッダー、フッターなどのページごとにノンブルや書誌情報などが含まれている可能性があります。
これらを修正・除去し、(文書の種類)として生成してください。
#(文書の種類)の定義<使用する言語やドキュメントの種類によって以下の項目は変更する。
・タイ語の公用文書
・国会での審議事項、決定事項
---プロンプト例ここまで---
ここまで整形できれば、翻訳はお好きな生成系AIを使ってください。
個人的には生成系AIの中でも、Chat GPTよりもGeminiのほうが使いやすい気がします。

そのあと、修正したテキストファイルから、コピー&ペーストなり、ファイルアップロードなどしてタイ語から翻訳してみてください。また、タイ語に関しては、個人的にはChatGPTよりもGeminiの翻訳精度が高いように思います。
ぜひお試し下さい。またわかりにくい点などありましたら、ご指摘ください。
主の平和。
余談ですが、今回のキャッチイメージは我が家のにゃんこの画像加工です。こんなのもできるんですね。驚きました。

